

Web scraping is the act of obtaining information from a website with the use of specific tools. There is a thin line between the legality and illegality of scraping some sites. This is why there are APIs (Application Programming Interface) available — they have endpoints that users can access to get information the company is willing to give out).
Of course, there are some information that might be required but they aren’t contained in the APIs. There are situations too in which companies API are not accessible to the public, also there are companies that don’t even have API. How does one get access to the data required in this case? Web Scraping.
Scraping a site can be done manually— this is the act of copying a certain data from a site, and pasting it for one’s use. It can also be automated — this is with the use of different advanced tools such as a programming language.
This article introduces web scraping with the use of python programming language(this covers the automation aspect) since everyone is familiar with the manual method.
Python has a couple of modules that can be used for web scraping; Requests and BeautifulSoup are introduced in this article.
NB: In order to understand web scraping efficiently, a solid understanding of HTML is required. This is because web scraping libraries will be called on html tags.
TODO
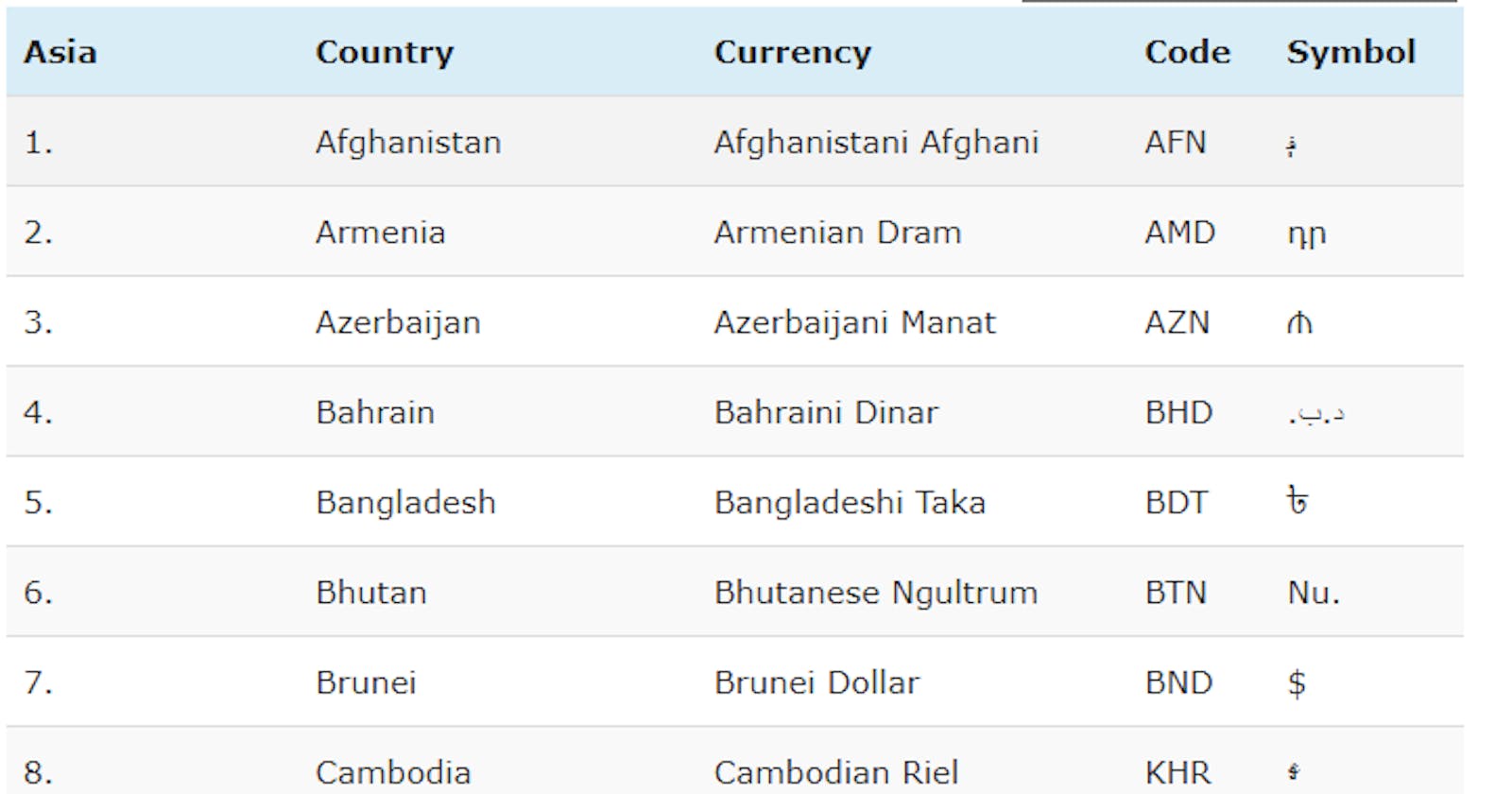
Scrape a website (thefactfile.org) to get information about a country.
PSEUDOCODE
- Install
requestsandBeautifulSoupmodule - Send a request to ‘factfile.org’, and get the response
- Pass the response to a
BeautifulSoupclass - Locate the data on the website and store it.
SHELL CODE
> pip install requests
> pip install beautifulsoup4
PYTHON CODE
import requests
From bs4 import BeautifulSoup
url = “https://thefactfile.org/countries-currencies-symbols/”
data = requests.get(url)
soup = BeautifulSoup(data.text, ‘html.parser’)
table_body = soup.find(‘table’)
all_country = [ ]
table_row_all = table_body.findAll(‘tr’)
a = 0
for table_row in table_row_all:
table_data_all = table_row.findAll(‘td’) or table_row.findAll(‘th’)
a_country = []
for table_data in table_data_all[1:]:
a_country.append(table_data.text)
continent = table_data_all[0].text
try:
float(continent)
except ValueError:
new_continent = continent
if a_country != [‘Country’, ‘Currency’, ‘Code’, ‘Symbol’]:
a_country.insert(0, new_continent)
all_country.append(a_country)
print(all_country)
CODE EXPLANATION
Requests module and BeautifulSoup class are imported
Requests is a HTTP(HyperText Transfer Protocol) library that allows querying of data from a server. i.e it acts like a web browser. BeautifulSoup Class helps to convert the HTML document into a data structure.A request is sent to the this page(this is similar to typing this in the search bar of a browser), and the response is stored in the
datavariable.BeautifulSoup class is then called, it takes the returned data and the type of parser(‘html.parser’) in this case as arguments. “The reason for a specific parser is to ensure same results across platforms and virtual environment”
An object of the BeautifulSoup class is created and stored in the
soupvariable.BeautifulSoup class inherits lot of methods, one of which is
find(). This takes a html tag — and/or it’s attribute — as it’s arguments, and returns the first instance of the tag specified.(the returned value is of type:bs4.element.Tag:)In the code snippet above, it returns the first instance of
<table>it encounters.The result is stored in variable table_body.
findAll()— another method inherited by BeautifulSoup is called on the variable. It also takes a html tag(and/or it’s attribute) as argument, and returns all the instance of the tag within the variable it’s called on. The value is returned in a list.In the code snippet above, it returns all the instance of
inside table_body. The table_body list is looped over, and return all the instances of
<tr> or <th>tag. The content of the<tr>/<th>tag is then stored in a list, which is further stored in another list—provided it passes the conditions stated.A list of list containing countries, their various currencies, symbols, currency abbreviation is then printed to the terminal.
How can the Python code be optimized? Let me know in the comment section.